What is AI, really?
Industry reflections | AI in medical imaging

Industry reflection
By Daniel Forsberg, Senior Research Scientist at Sectra
The hype surrounding artificial intelligence (AI) is prevalent in all industries today. Healthcare is no exception. AI often takes center stage at various meetings, tradeshows and scientific conferences. However, while the hype has been increasing in medical imaging—especially over the past few years—we are still waiting to see how AI will be implemented and deployed in the daily work of image diagnostics and what the clinical impact will be.
Over the past few years, the Society for Imaging Informatics in Medicine (SIIM), a professional organization at the intersection of medical imaging and information technologies, has witnessed the same trend at their annual meetings as seen elsewhere: growing AI hype. SIIM is an interdisciplinary society consisting of physicians, researchers, IT professionals and others, all interested and actively engaged in shaping the future of imaging informatics. As such, the members of SIIM and others attending their meetings care deeply about solving actual problems and being able to provide better care today. This can be contrasted with more traditional scientific meetings, where the focus is not always on real-world or the most relevant problems, but rather on providing novel solutions.
In less than a month’s time, the SIIM 2018 Annual Meeting will take place in National Harbor, Maryland in the US. An integral part of the SIIM annual meeting is the scientific sessions where researchers present their latest work. Based on the scientific abstracts to be presented, the purpose of this article is to specify current findings on AI in medical imaging informatics and to discuss the impressions of these findings, with the intention to understand where we are at and where we might be heading next.
At this year’s annual meeting, a total of 90 scientific abstracts will be presented (available for download here). The oral presentations for this year have been divided into the following tracks:
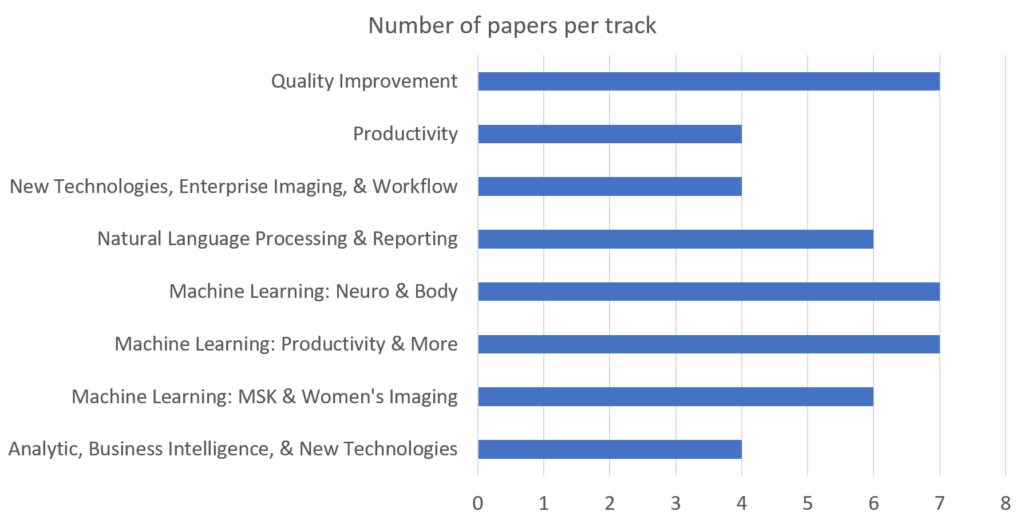
We can assume that the abstracts presented as posters (45 in total) follow a similar topical distribution. Already from this we can note that AI, which in this context includes both machine learning (ML) and natural language processing (NLP), is a recurring and important theme.
After quickly reviewing all 90 abstracts, 40 of them were found to deal with AI in one way or another. Reviewing the content of the 40 AI-related abstracts, the following was found:
30 abstracts reported on work where an algorithm was trained for a specific task. The tasks were distributed as follows:
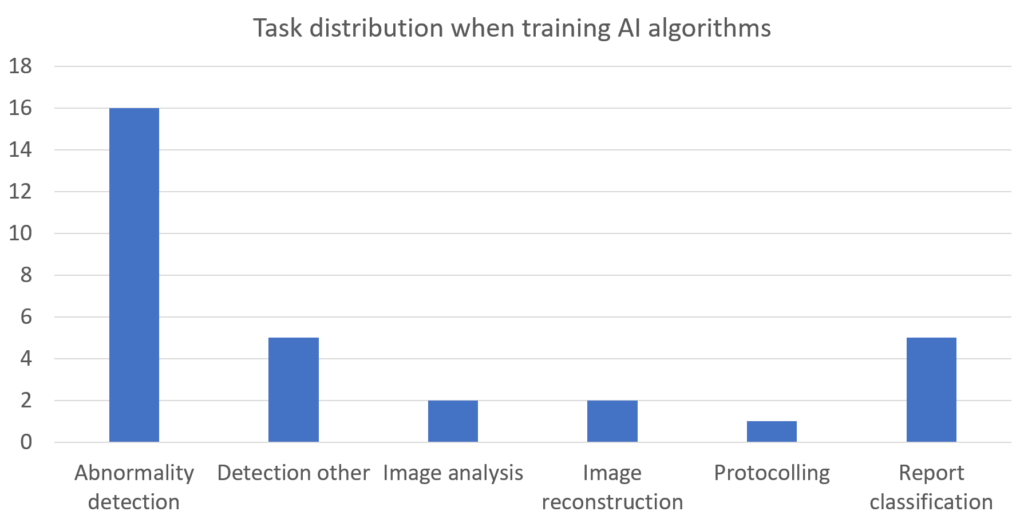
In this context, the task “Detection other” includes gender, follow-up recommendation, protocol, scan range and view detection, and the task “Image analysis” includes segmentation and registration.
Most of these papers used a deep learning (DL) approach (20 of them, primarily convolutional neural networks), 12 used traditional ML (such as support vector machine, Naïve Bayes, random forests and logistic regression) and eight used NLP. Many of the DL papers employed well-known network architectures, such as AlexNet, VGG Net, GoogLeNet or ResNet, either pretrained on ImageNet or trained from scratch. 23 used images of some kind as a data source and eight used textual data. For images, the most common modalities were x-rays, MR and CT.
Three abstracts considered clinical deployment and/or evaluation in their work, rather than only considering, for instance, the traditional evaluation of an algorithm, such as sensitivity, specificity, etc. One of these abstracts also included algorithm training, but only considered the deployment of the algorithm in a clinical environment with no evaluation. The second of these abstracts evaluated how an algorithm affected users depending on whether the results from the algorithm were presented at the start of the review process or afterwards. The third abstract employed simulation software to investigate how different settings of sensitivity and specificity would affect the situation in an emergency workflow.
Access to relevant and sufficient data is of utmost importance when training AI algorithms. As an indication of this, four abstracts dealt with questions related to how existing data in healthcare systems can be leveraged to extract data relevant for training of AI algorithms. The following graph shows how the dataset size varied among the abstracts that trained an algorithm.
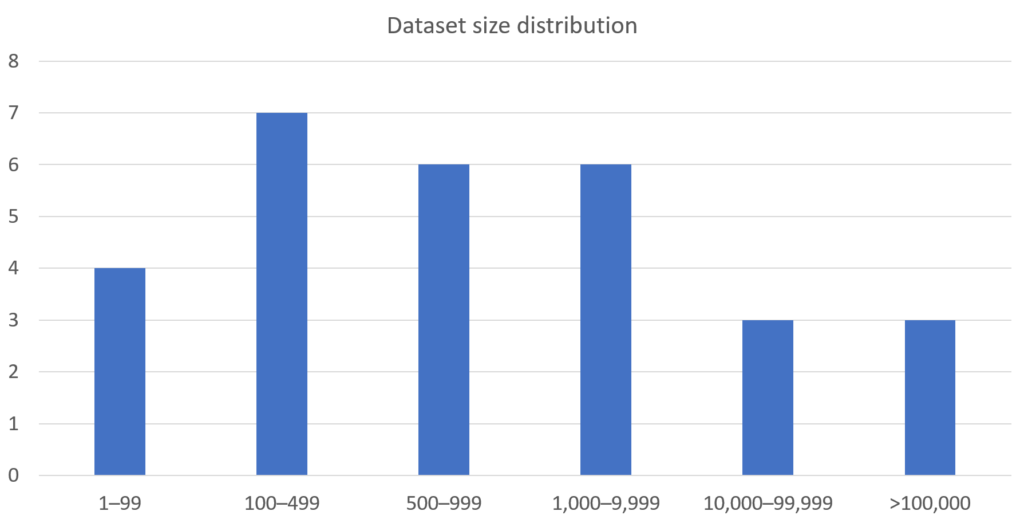
The observant reader will notice that only 29 abstracts are accounted for here. This because one of the abstracts did not provide information on this matter.
The AI trend will be a prevalent theme at the annual meeting of SIIM, as just under half (44%) of the abstracts dealt with AI—despite the fact that SIIM has a separate meeting devoted solely to AI and that several other meetings and conferences have emerged in recent years. This is further emphasized by the fact that four out of eight oral presentation tracks are dedicated to AI (ML and NLP).
Among the abstracts that trained an actual algorithm, two thirds utilized DL. This shows that even though traditional ML algorithms can be and are being used, it is primarily DL that is driving the current interest. In terms of data size used during training, it was interesting to note that although DL was often used together with the very large datasets, DL algorithms were still used when only smaller datasets were available, meaning less than 100 cases. This shows two things in my opinion: 1) large datasets in and of themselves are not a prerequisite for training DL algorithms, although a well-distributed dataset is needed to properly evaluate the generalizability of a trained model, and 2) gaining access to large datasets is still challenging. The latter is evident given that many had less than 1,000 cases (57%), which I am confident was not free choice but rather a consequence of not having access. The situation would be even worse if not for some of the public datasets that are frequently used.
Going forward in terms of access to training data, efforts to extract data that can be used for training of AI algorithms are of utmost importance. Some will be presented at SIIM 2018, but more work is necessary, and it is pivotal to understand that it is insufficient to simply extract image data from a PACS based on using NLP applied to the free-text reports. More work is needed before the data can be reliably used to train AI algorithms. For a longer piece on different levels of data readiness for AI, please read this post by Dr. Hugh Harvey.
A troubling finding was the fact that so few of the submitted abstracts considered aspects of clinical deployment and evaluation. Surely it is of interest to consider sensitivity, specificity, F1 scores, the area under curve, etc., but these are primarily to be used as sanity checks for algorithms and to compare different algorithms. The value of an algorithm cannot be properly evaluated unless it is deployed in a clinical setting, integrated into the daily work and evaluated by the intended end users. A noteworthy exception here was an abstract focused on evaluating the impact of an algorithm on an emergency care workflow given different sensitivity and specificity values for the detection algorithms using simulations.
AI remains a strong trend, but we still lack cases detailing actual clinical deployment and evaluation in a variety of situations. Moreover, it is evident that access to relevant training data is still an issue when training algorithms.
Looking ahead, I would like to encourage:
Unfortunately, I will not be able to attend SIIM myself this year, but I am certain of a successful SIIM meeting, considering the great program that has been prepared. I look forward to hearing about the meeting from my colleagues and from you readers. What do you think is an important next step if we are to see more AI deployed in clinical practice? Please reach out directly to me or join us at an upcoming event.
This article was originally published on LinkedIn: AI in medical imaging informatics—a SIIM 2018 perspective